
Reinforcement Learning is a powerful machine learning technique where an agent learns to make optimal decisions in an environment by interacting with it and receiving rewards or penalties. Imagine teaching a dog a trick – you reward good behavior and correct bad behavior. Reinforcement learning works similarly, using trial and error to find the best strategy for achieving a goal.
This approach has led to breakthroughs in various fields, from game playing to robotics.
This guide delves into the core concepts of reinforcement learning, exploring different algorithms, the exploration-exploitation dilemma, and the exciting possibilities of deep reinforcement learning. We’ll examine both model-based and model-free approaches, compare on-policy and off-policy learning, and discuss the challenges and future directions of this rapidly evolving field. Through illustrative examples and a frequently asked questions section, we aim to provide a clear and comprehensive understanding of this fascinating area of artificial intelligence.
Daftar Isi :
Introduction to Reinforcement Learning
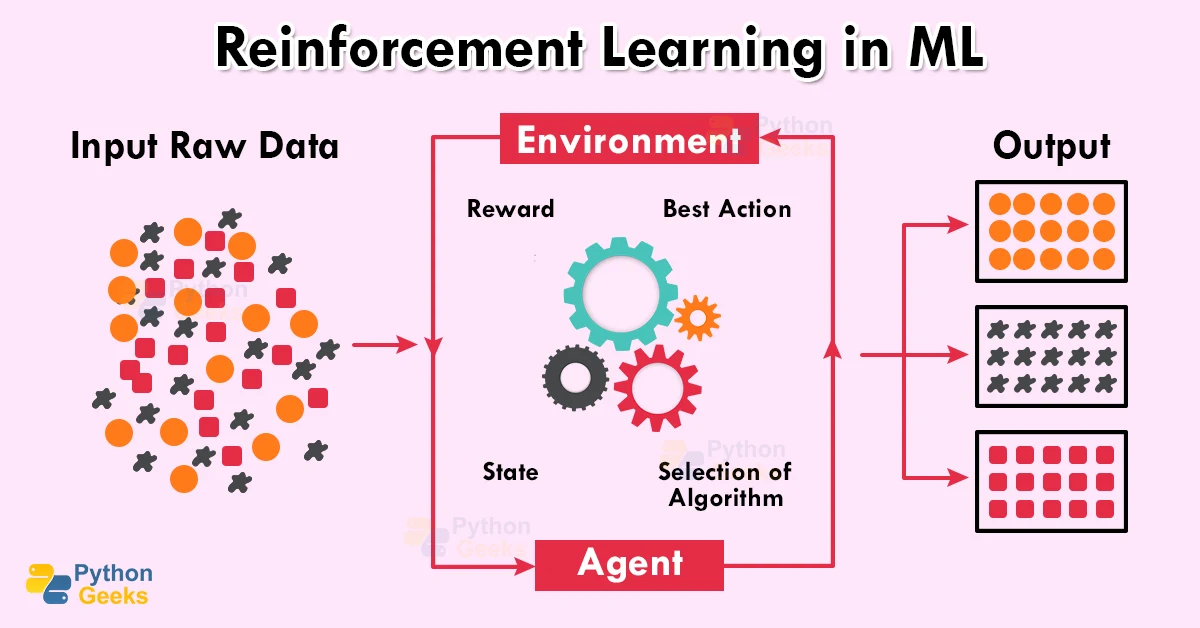
Reinforcement learning (RL) is a powerful machine learning technique where an agent learns to interact with an environment by trial and error, aiming to maximize a cumulative reward. Unlike supervised learning which relies on labeled data, RL learns through experience, receiving feedback in the form of rewards or penalties. This iterative process allows the agent to discover optimal strategies for achieving its goals.Reinforcement learning operates on the principle of learning through interaction.
An agent takes actions within an environment, observes the resulting state, and receives a reward signal indicating the desirability of the outcome. Based on this feedback, the agent adjusts its behavior, refining its strategy over time to achieve higher rewards. This feedback loop is central to the learning process.
Core Concepts of Reinforcement Learning
Reinforcement learning revolves around four key concepts: the agent, the environment, rewards, and policies. The agent is the learner and decision-maker, interacting with the environment. The environment is everything outside the agent, presenting states and providing rewards. Rewards are numerical signals that indicate the desirability of states and actions. Policies define the agent’s behavior, mapping states to actions.
A good policy maximizes the expected cumulative reward.
A Simple Analogy: Learning to Ride a Bicycle
Imagine learning to ride a bicycle. You (the agent) are interacting with the environment (the road, the bicycle). Your actions (pedaling, steering, balancing) influence your state (speed, balance, position). A positive reward could be staying upright and moving forward, while a negative reward would be falling over. Through repeated trials, adjusting your actions based on the consequences (rewards/penalties), you learn the policy (the skill) of riding a bicycle.
Reinforcement learning is all about teaching agents to make optimal decisions through trial and error. Think of it like training a dog – you reward good behavior. Interestingly, the concept of focusing on specific elements, like rewarding a clear image, relates to photography; if you want to understand the importance of a focused subject against a blurred background, check out this article on Apa itu Bokeh?
to see how a similar principle of selective focus applies. This selective focus is analogous to how reinforcement learning algorithms prioritize certain actions over others.
Real-World Applications of Reinforcement Learning
Reinforcement learning has found success in diverse applications. In robotics, RL algorithms enable robots to learn complex manipulation tasks, such as grasping objects or assembling products, by rewarding successful actions and penalizing failures. In game playing, RL has achieved superhuman performance in games like Go and chess, demonstrating its capacity to learn intricate strategies. Furthermore, RL is being used to optimize resource allocation in data centers, improving energy efficiency and performance.
In personalized recommendations, RL algorithms can learn user preferences and deliver tailored suggestions, enhancing user experience and engagement. Finally, RL is increasingly being explored in areas like autonomous driving, traffic control, and finance, showcasing its broad applicability.
Types of Reinforcement Learning
Reinforcement learning (RL) algorithms can be categorized in several ways, leading to a rich landscape of approaches for solving different problems. Understanding these categorizations is crucial for selecting the appropriate algorithm for a specific task. We’ll focus on two key distinctions: model-based versus model-free, and on-policy versus off-policy learning.
Reinforcement learning trains AI agents to make decisions through trial and error, learning from rewards and penalties. Understanding how these agents behave is crucial, especially considering the implications for human interaction. This is highlighted by research into the social and psychological effects of interacting with AI robots , which helps us design more responsible and beneficial reinforcement learning systems.
Ultimately, ethical considerations in reinforcement learning are becoming increasingly important as AI robots become more sophisticated.
Model-Based vs. Model-Free Reinforcement Learning
Model-based RL algorithms build an internal model of the environment. This model predicts the next state and reward given the current state and action. The agent uses this model to plan its actions, often by simulating future interactions within the model. Model-free methods, on the other hand, don’t explicitly build a model. They learn directly from experience, updating their policies based on observed transitions and rewards without attempting to understand the underlying dynamics of the environment.Model-based methods can be more sample-efficient, as they can learn from simulated experiences rather than relying solely on real interactions with the environment.
However, building an accurate model can be challenging, and if the model is inaccurate, the agent’s actions may be suboptimal. Model-free methods are simpler to implement and are generally more robust to model inaccuracies, but they often require significantly more interactions with the environment to learn effectively. Consider a robot learning to navigate a maze: a model-based approach might build a map of the maze and plan a path, while a model-free approach would learn the optimal path through trial and error.
On-Policy vs. Off-Policy Reinforcement Learning
The distinction between on-policy and off-policy learning revolves around how the agent updates its policy. On-policy algorithms learn directly from the actions taken by the current policy. The agent improves its policy based on its own experiences. Off-policy algorithms, conversely, learn from experiences generated by a different policy, often a behavior policy. This allows them to learn from data collected from past experiences or from other agents.On-policy methods are generally simpler to understand and implement, but they can be less sample-efficient, as the agent must constantly update its policy while exploring the environment.
Off-policy methods can be more sample-efficient, as they can reuse data from previous experiences, but they are often more complex and can be sensitive to the choice of behavior policy. For example, an on-policy algorithm might learn to play a game by only using the actions it chooses itself, whereas an off-policy algorithm could learn from watching a human player or from a different, older version of its own policy.
Comparison of Reinforcement Learning Algorithms
The following table compares several popular reinforcement learning algorithms, highlighting their strengths and weaknesses:
| Algorithm Name | Type | Strengths | Weaknesses |
|---|---|---|---|
| Q-learning | Off-policy, Model-free | Simple to implement, converges to optimal policy under certain conditions, relatively stable. | Can be slow to converge, sensitive to exploration strategy, requires careful tuning of hyperparameters. |
| SARSA | On-policy, Model-free | More stable than Q-learning, less prone to overestimation bias. | Slower convergence than Q-learning, less sample efficient. |
| Deep Q-Networks (DQN) | Off-policy, Model-free | Can handle high-dimensional state spaces, successful in many complex tasks (e.g., game playing). | Computationally expensive, can be unstable, requires careful consideration of experience replay and target network updates. |
Exploration vs. Exploitation
In reinforcement learning, an agent constantly faces a fundamental dilemma: should it exploit what it already knows works well, or explore uncharted territory to potentially discover even better strategies? This exploration-exploitation trade-off is crucial for an agent’s learning success. A perfectly balanced approach is essential for maximizing cumulative rewards over time. Too much exploitation leads to stagnation, while excessive exploration can result in missed opportunities for immediate rewards.The exploration-exploitation dilemma arises because an agent needs to balance the immediate gratification of exploiting its current knowledge against the potential long-term benefits of exploring new actions and states.
An agent that only exploits will quickly converge to a suboptimal policy if its initial knowledge is inaccurate or incomplete. Conversely, an agent that only explores might never find a good policy, constantly trying new actions without ever settling on a successful strategy.
Epsilon-Greedy Strategy, Reinforcement Learning
The ε-greedy strategy is a simple yet effective approach to balancing exploration and exploitation. It involves selecting the action with the highest estimated value with probability 1-ε, and selecting a random action with probability ε. The parameter ε controls the degree of exploration; a higher ε value means more exploration, while a lower value prioritizes exploitation. For example, with ε=0.1, the agent will explore randomly 10% of the time and exploit its current best knowledge 90% of the time.
This strategy allows for gradual reduction of ε over time, starting with a higher value for initial exploration and decreasing it as the agent gains more experience. This ensures sufficient exploration early in the learning process and a shift towards exploitation as the agent becomes more confident in its knowledge.
Softmax Strategy
The softmax strategy offers a more nuanced approach compared to ε-greedy. Instead of a simple probability threshold, softmax assigns probabilities to each action based on their estimated values. These probabilities are then used to select an action. The formula is:
P(ai) = exp(Q(a i)/τ) / Σ j exp(Q(a j)/τ)
where P(a i) is the probability of selecting action a i, Q(a i) is the estimated value of action a i, and τ is a temperature parameter. A higher τ value leads to more exploration (probabilities are more uniform), while a lower τ value favors exploitation (higher probability for actions with higher estimated values). Unlike ε-greedy, softmax always allows for some exploration, even when exploiting the best action.
This can be particularly useful in scenarios with many similar actions.
Scenario Illustrating Poor Exploration-Exploitation Balance
Imagine a robot tasked with navigating a maze to find a reward. The robot uses Q-learning to learn the optimal path. If the robot only exploits (ε=0), and it initially takes a path that leads to a dead end, it will never discover the path to the reward, even if a better path exists. Conversely, if the robot only explores (ε=1), it will randomly wander the maze without learning an efficient path to the reward, spending a significant amount of time and energy without achieving its goal.
A balanced approach, starting with a higher ε and gradually decreasing it, allows the robot to initially explore different paths, discover the reward, and then refine its strategy by exploiting the learned optimal path.
Deep Reinforcement Learning
Source: pythongeeks.org
Deep reinforcement learning (DRL) combines the power of deep learning with the framework of reinforcement learning. This powerful combination allows agents to learn complex behaviors directly from raw sensory input, without the need for extensive hand-engineered features. Instead of relying on pre-defined state representations, DRL uses neural networks to approximate value functions or policies, enabling the learning of sophisticated strategies in high-dimensional environments.Deep learning techniques are integrated into reinforcement learning primarily by using neural networks to represent the agent’s policy or value function.
The neural network takes the agent’s current state as input and outputs either the action to take (in the case of a policy network) or an estimate of the expected future reward (in the case of a value network). The network’s weights are then adjusted through the reinforcement learning algorithm based on the rewards received by the agent.
This allows the agent to learn increasingly effective strategies over time.
Deep Reinforcement Learning Algorithms
Several key algorithms leverage deep learning within the reinforcement learning paradigm. These algorithms differ in their approach to approximating the value function or policy and how they update the network’s weights.
- Deep Q-Networks (DQN): DQN uses a deep neural network to approximate the Q-function, which estimates the expected cumulative reward for taking a specific action in a given state. It employs techniques like experience replay (storing past experiences and sampling randomly from them) and target networks (using a separate network to estimate the target Q-values) to improve stability and learning efficiency.
DQN has achieved significant success in various games, including Atari games.
- Proximal Policy Optimization (PPO): PPO is a policy gradient method that aims to improve the policy iteratively while preventing large updates that can destabilize training. It achieves this by constraining the policy updates, ensuring that the new policy doesn’t deviate too much from the old one. PPO is known for its robustness and ease of implementation, making it a popular choice for many applications.
- Actor-Critic Methods: Actor-critic methods employ two neural networks: an actor network that selects actions and a critic network that evaluates the actions taken by the actor. The critic provides feedback to the actor, allowing it to improve its policy. Examples include A2C (Advantage Actor-Critic) and A3C (Asynchronous Advantage Actor-Critic). These methods often exhibit faster convergence compared to pure policy gradient methods.
Deep Q-Network Application in CartPole
The CartPole environment is a classic reinforcement learning problem where an agent must balance a pole on a cart by applying forces to the cart. Let’s consider a DQN solution.The architecture of the DQN for CartPole might consist of a simple fully connected neural network. The input layer would receive four values representing the cart’s position, cart’s velocity, pole’s angle, and pole’s angular velocity.
The network would then consist of one or more hidden layers with ReLU activation functions, followed by an output layer with two neurons, each representing the Q-value for either pushing the cart left or right.Training involves repeatedly interacting with the environment. At each time step, the agent observes the state, selects an action using an ϵ-greedy strategy (exploring with probability ϵ and exploiting with probability 1-ϵ), receives a reward (1 for balancing the pole, 0 for failure), and observes the next state.
This experience (state, action, reward, next state) is stored in a replay buffer. Batches of experiences are then sampled from the replay buffer and used to train the DQN using a loss function that minimizes the difference between the predicted Q-values and the target Q-values (calculated using the Bellman equation). The target network is periodically updated with the weights of the main network.
This process continues until the agent learns to balance the pole effectively. The hyperparameters, such as the learning rate, discount factor, and ϵ, are carefully tuned to optimize performance. For example, a learning rate of 0.001, a discount factor of 0.99, and an initial ϵ of 1 (decaying to 0.1) might yield good results.
Challenges and Future Directions
Reinforcement learning, while demonstrating impressive capabilities, still faces significant hurdles in its application to real-world scenarios. These challenges stem from both the inherent complexity of the learning process and the limitations of current algorithms and computational resources. Overcoming these obstacles is crucial for unlocking the full potential of RL in diverse fields.The successful application of reinforcement learning hinges on several critical factors.
Addressing these challenges will pave the way for more robust and reliable RL systems.
Reward Function Design
Designing effective reward functions is arguably the most significant challenge in applying reinforcement learning. A poorly designed reward function can lead the agent to learn unintended or even harmful behaviors, a phenomenon often referred to as reward hacking. For example, in a robotics task where the goal is to pick up an object, a simple reward based solely on proximity to the object might incentivize the robot to repeatedly nudge the object without actually grasping it.
A more sophisticated reward function would need to incorporate successful grasping and secure object handling. Effective reward design often requires deep domain expertise and careful consideration of potential unintended consequences. Research into automated reward function design and techniques for shaping rewards to guide agents towards desired behaviors is actively ongoing.
Sample Efficiency
Many reinforcement learning algorithms require a vast amount of data to learn effectively. This data is often obtained through trial and error, which can be expensive, time-consuming, or even dangerous in real-world applications, such as autonomous driving or medical robotics. Improving sample efficiency – the ability to learn effectively from limited data – is a crucial area of research.
Techniques like transfer learning, where knowledge learned in one task is applied to another, and meta-learning, which aims to learn how to learn, hold significant promise in this regard. For instance, a robot trained to grasp various objects in a simulated environment could leverage this learned knowledge to quickly adapt to new objects in the real world, significantly reducing the need for real-world training data.
Reinforcement learning is all about teaching agents to make optimal decisions through trial and error. Think of it like training a dog – you reward good behavior. This process can even be applied to video editing; imagine optimizing the workflow in a video editor like Kinemaster Pro Mod apk to find the fastest and most efficient way to edit a video.
Ultimately, reinforcement learning aims to automate this optimization, leading to improved efficiency and potentially better results in various fields.
Safety and Robustness
Deploying reinforcement learning agents in real-world settings necessitates robust safety mechanisms. Agents should be able to handle unexpected situations, avoid catastrophic failures, and operate reliably in unpredictable environments. Ensuring safety often requires incorporating constraints into the learning process, such as preventing the agent from taking actions that could be harmful. Formal methods, which use mathematical techniques to verify the correctness and safety of algorithms, are increasingly being integrated into RL research to address these concerns.
For example, in autonomous driving, safety mechanisms might include emergency stops or fail-safes to prevent accidents.
Future Directions and Open Research Questions
The field of reinforcement learning is rapidly evolving, with numerous promising avenues for future research.
- Developing more sample-efficient algorithms that can learn effectively from limited data.
- Creating robust and safe reinforcement learning agents that can operate reliably in unpredictable environments.
- Designing automated methods for reward function design that avoid unintended consequences.
- Exploring the integration of reinforcement learning with other machine learning paradigms, such as supervised and unsupervised learning.
- Developing algorithms that can handle complex, high-dimensional state and action spaces.
- Addressing the challenge of explainability in reinforcement learning, making it easier to understand why an agent makes certain decisions.
- Investigating the use of reinforcement learning for solving problems in areas such as healthcare, finance, and climate change.
- Developing more efficient and scalable algorithms for deep reinforcement learning.
Illustrative Examples
Reinforcement learning’s power is best understood through concrete examples. Its applications span diverse fields, showcasing its adaptability and potential. We’ll examine two key areas: robotics and game playing, highlighting the core components and challenges involved.
Reinforcement learning is all about teaching agents to make optimal decisions through trial and error. Imagine training an AI to edit videos – it could learn to improve its editing skills by watching and analyzing results. To get started with video editing, you might want to check out some free PC software like those listed on this site: Aplikasi Edit Video PC Gratis.
Once you have the tools, you can then apply concepts of reinforcement learning to automate or optimize certain aspects of your video editing workflow.
Reinforcement Learning in Robotics
Consider a robot arm tasked with picking up objects of varying shapes and sizes from a conveyor belt. This scenario perfectly illustrates the elements of a reinforcement learning system. The robot arm acts as the
- agent*, constantly interacting with its
- environment* – the conveyor belt and the objects upon it. The
- reward* system is designed to incentivize successful object grasping and placement. For example, a positive reward is given for successfully picking up an object and placing it in a designated area, while negative rewards might penalize collisions or dropped objects. The
- policy*, learned through the reinforcement learning algorithm, dictates the actions the robot arm takes (e.g., adjusting gripper pressure, moving to specific coordinates) based on the current state of the environment (e.g., object size, position). Over time, the robot refines its policy, improving its success rate in object manipulation. Different algorithms, like Q-learning or Deep Q-Networks (DQN), could be employed, each with its own strengths and weaknesses in handling the complexity of the robotic task.
The algorithm learns through trial and error, iteratively adjusting its actions to maximize the cumulative reward.
A robotic arm learns to grasp objects by receiving positive rewards for successful pickups and negative rewards for failures, refining its actions through iterative learning.
Reinforcement Learning in Game Playing
The application of reinforcement learning in game playing, particularly in complex games like Go and chess, has yielded remarkable results. AlphaGo, developed by DeepMind, famously defeated a world champion Go player, showcasing the power of deep reinforcement learning. In these games, the agent is the AI player, the environment is the game itself (including the rules and the opponent’s moves), and the reward is typically winning the game (or achieving a high score).
The policy defines the AI’s strategy – which moves to make in various game situations.The challenges in game playing applications include the immense size of the state space (all possible game configurations) and the need for efficient exploration strategies to discover effective moves without resorting to brute-force search. Furthermore, the stochastic nature of some games (involving elements of chance) adds complexity.
Despite these challenges, reinforcement learning has achieved significant successes, demonstrating superhuman performance in various games. The use of deep neural networks allows the AI to learn complex patterns and strategies directly from game experience, eliminating the need for explicit programming of rules.
AlphaGo’s victory over a Go champion highlights reinforcement learning’s ability to master complex games by learning optimal strategies through self-play and reward maximization.
Last Point
Reinforcement learning presents a compelling approach to problem-solving, offering a path to creating intelligent agents capable of adapting and learning in complex environments. While challenges remain in areas like reward function design and sample efficiency, the ongoing research and advancements in deep reinforcement learning promise exciting developments in the future. From mastering complex games to optimizing real-world processes, the potential applications are vast and continue to inspire innovation.
This guide has provided a foundational understanding, encouraging further exploration of this dynamic field.
Questions and Answers
What is the difference between a reward and a penalty in reinforcement learning?
A reward is a positive signal that encourages the agent to repeat a specific action, while a penalty is a negative signal that discourages it. They guide the learning process.
How does reinforcement learning differ from supervised learning?
Supervised learning uses labeled data to train a model, while reinforcement learning learns through trial and error, receiving feedback in the form of rewards and penalties.
What are some common applications of reinforcement learning beyond gaming and robotics?
Reinforcement learning is used in resource management (e.g., optimizing energy grids), personalized recommendations (e.g., suggesting products), and finance (e.g., algorithmic trading).
Is reinforcement learning always guaranteed to find the optimal solution?
No, the optimal solution is not always guaranteed. The agent’s performance depends on factors like the reward function design, the algorithm used, and the exploration-exploitation strategy.
What are some ethical considerations related to reinforcement learning?
Ethical concerns include bias in training data leading to unfair outcomes, the potential for unintended consequences, and ensuring the safety and reliability of reinforcement learning systems in real-world applications.